Accelerating AI/ML Workflows in Earth Sciences with GPU-Native Xarray and Zarr (and more!)
Thursday, May 1st, 2025 (about 1 month ago)
Accelerating AI/ML Workflows in Earth Sciences with GPU-Native Xarray and Zarr (and more!)#
TL;DR#
This is a long blog post, but if you want the TL;DR, here it is: Earth science AI/ML workflows are often bottlenecked by slow data loading, leaving GPUs underutilized while CPUs struggle to feed large climate datasets like ERA5. In this blog post, we discuss how to build a GPU-native pipeline using Zarr v3, CuPy, KvikIO, and NVIDIA DALI to accelerate data throughput. We walk through profiling results, chunking strategies, direct-to-GPU data reads, and GPU-accelerated preprocessing, all aimed at maximizing GPU usage and minimizing I/O overhead.
The result: faster training, higher throughput, and a scalable path forward for geoscience ML workflows. 🌍🤖🚀
Introduction#
In large-scale geospatial AI and machine learning workflows, data loading is often the main bottleneck. Traditional pipelines rely on CPUs to preprocess and transfer massive datasets from storage to GPU memory, consuming resources and limiting scalability and effective use of GPU resources.
To tackle this issue, a team from the NSF National Center for Atmospheric Research (NSF-NCAR) and Development Seed with mentors from NVIDIA participated in an OpenHackathon to demonstrate how AI/ML workflows in Earth system sciences can benefit from GPU-native technologies using tools such as Zarr, KvikIO, and DALI.
In this post, we share our hackathon experience, the integration strategies we explored, and the performance gains we achieved to highlight how modern tools can transform data-intensive workflows.
Problem#
ML pipelines for large scientific datasets typically include the following steps:
- Reading raw data from disk or object storage (IO-bound)
- Transforming / preprocessing data (often CPU-bound)
- Model training / inference (often GPU-bound)
Although GPU compute is incredibly fast, I/O & CPU can become a bottleneck when dealing with large datasets. In an ideal scenario, we want to saturate the GPU with data as quickly as possible to minimize idle time on both the CPU and GPU.
In this hackathon, we explored several strategies to reduce the data loading bottleneck and build a GPU-native pipeline to maximize GPU utilization.
Data & Code Overview 📊#
For this hackathon, we developed a benchmark of training a U-Net (with ResNet encoder) model on the ERA-5 Dataset to predict next time steps. The training pipeline used a standard PyTorch DataLoader and supported both single-GPU and multi-GPU training via Distributed Data Parallel (DDP). The full benchmark repo is available here.
Initial Performance Bottlenecks#
First, we used NVIDIA's Nsight Systems to profile our code and identify performance bottlenecks.
The initial profiling results clearly showed that the data loading step was the main bottleneck in our pipeline, with minimal overlap between CPU and GPU compute steps, which meant that the GPU was often idle while waiting for the CPU to load data.
Here are some screenshots of the profiling results:
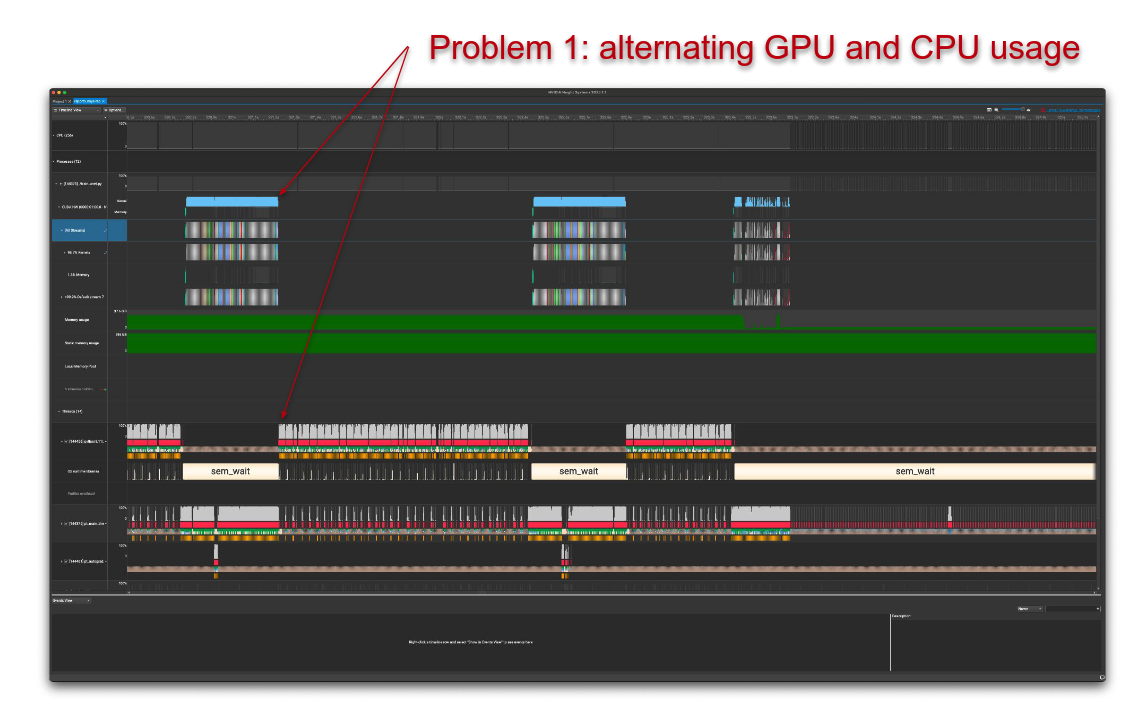
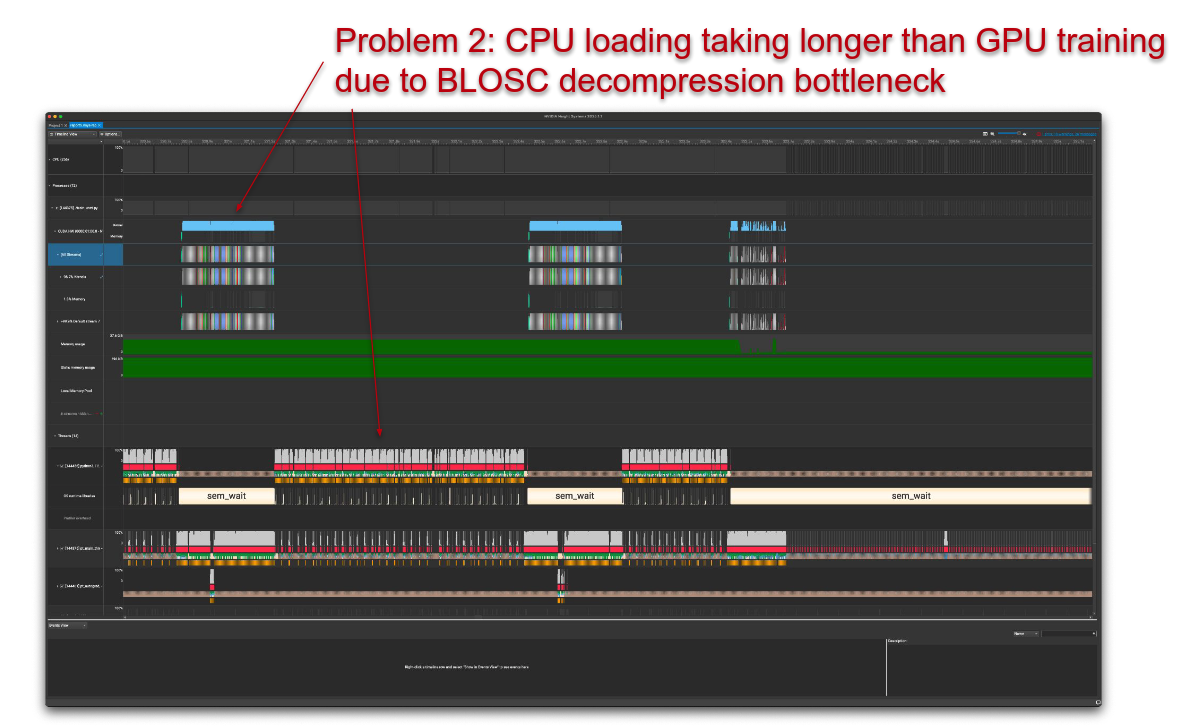
We further quantified this bottleneck by comparing data loading and training throughput, as shown in the figure below (higher bars/more throughput is better):
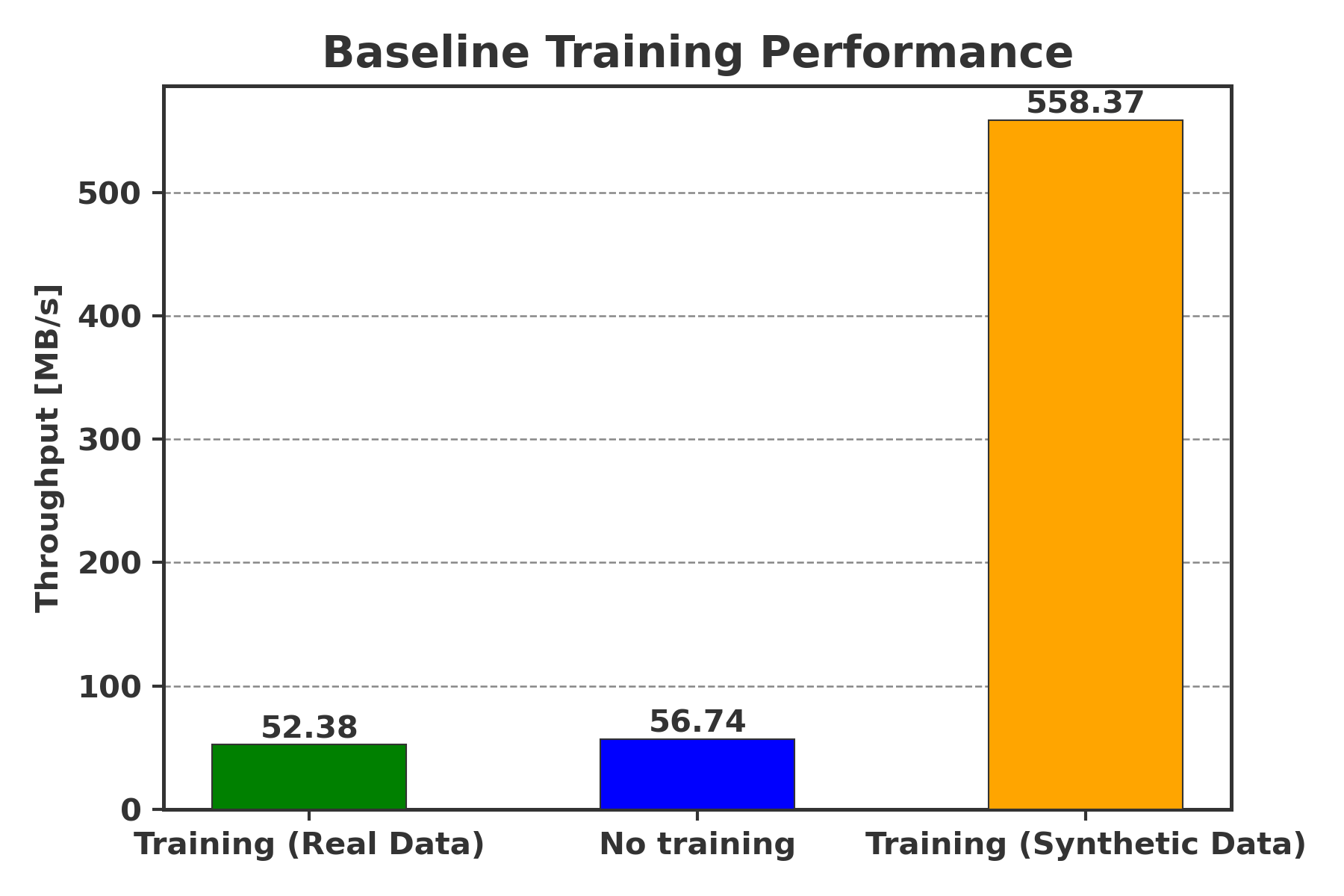
In the plot above, the three bars represent:
- Training (Real Data): Baseline throughput of the end-to-end pipeline reading real data from disk.
- No Training (i.e. data loading throughput): Throughput of the data loading without any training (to measure the time spent on data loading vs. training).
- Synthetic Data (i.e. Training throughput): Throughput of the data loading using synthetic data (to remove the data loading bottleneck).
The results show that the data loading step is the main bottleneck in our pipeline, with much lower throughput compared to the training step.
Hackathon: Strategies Explored!#
During the hackathon, we tested the following strategies to improve the data loading performance. In the end, we were able to achieve a **
Step 1: Optimized Chunking & Compression#
The copy of the ERA5 dataset we were using initially had a suboptimal chunking scheme of {'time': 10, 'channel': C, 'height': H, 'width': W}, which meant that a minimum of 10 time steps of data was being read even if we only needed 2 consecutive time steps.
We decided to rechunk the data to align with our access pattern of 1-timestep at a time, while reformating to Zarr format 3.
The full script is available here, with the main code looking like so:
1import xarray as xr 2 3ds: xr.Dataset = xr.open_mfdataset("ERA5.zarr") 4# Rechunk the data 5ds = ds.chunk({"time": 1, "level": 1, "latitude": 640, "longitude": 1280}) 6# Save to Zarr v3 7ds.to_zarr("rechunked_ERA5.zarr", zarr_version=3) 8
For more optimal performance, consider:
- Decompression: If you're not transferring over a network (e.g. reading from local disk ), consider storing the data without compression, since decompresion can slow down read speeds. But see also GPU decompression with nvCOMP below. 😉
- Align chunks with model access patterns: Proper chunk alignment reduces the number of read operations, avoids unnecessary data loading, and improves GPU utilization.
- Avoid Excessively Small or Large Chunks: Having too many small chunks can degrade read speeds by increasing metadata overhead and I/O operations. As a general rule of thumb, a compressed chunk should be
>1MB,<100MBfor optimal reads. Consider concatenating several data variables together if a single chunk size is too small (<1MB), even at the expense of reducing readability of the Zarr store.- Alternatively, sharding support for GPU buffers has been recently added to Zarr. Consider using
zarr-python >= 3.0.8if you want to fully benfit from sharded storage with GPU compatibility. The plot below shows the performance of the original dataset vs. the rechunked dataset (to optimal chunk size) vs. uncompressed Zarr format 3 dataset.
- Alternatively, sharding support for GPU buffers has been recently added to Zarr. Consider using

Step 2: Direct to GPU Data Reading with Zarr v3 (+ KvikIO) 📖#
One of the exciting features of Zarr Python 3 is the ability to read data directly into CuPy arrays (i.e. GPU memory). 🎉
Specifically, you can either use the zarr-python driver to read data from zarr->CPU->GPU, or the kvikio driver to read data from zarr->GPU directly!
To benefit from these new features, we recommend installing:
Option 1: GPU-backed arrays via zarr-python (Zarr->CPU->GPU)
The example below shows how to read a Zarr store into CuPy arrays by usingzarr.config.enable_gpu():
1import cupy as cp 2import xarray as xr 3import zarr 4 5airt = xr.tutorial.open_dataset("air_temperature", engine="netcdf4") 6airt.to_zarr(store="/tmp/air-temp.zarr", mode="w", zarr_format=3, consolidated=False) 7 8with zarr.config.enable_gpu(): 9 ds = xr.open_dataset("/tmp/air-temp.zarr", engine="zarr", consolidated=False) 10 assert isinstance(ds.air.data, cp.ndarray) 11
⚠️ Note that using engine="zarr" like above would still result in data being loaded into CPU memory before being transferred to GPU memory.
II. Option 2: Direct-to-GPU via KvikIO (Zarr -> GPU)
If your system supports GPU Direct Storage (GDS), you can use kvikio to read data directly into GPU memory, bypassing CPU memory.
Here is a minimal example of how to do this:
1import kvikio.zarr 2 3with zarr.config.enable_gpu(): 4 store = kvikio.zarr.GDSStore(root="/tmp/air-temp.zarr") 5 ds = xr.open_dataset(filename_or_obj=store, engine="zarr") 6 assert isinstance(ds.air.data, cp.ndarray) 7
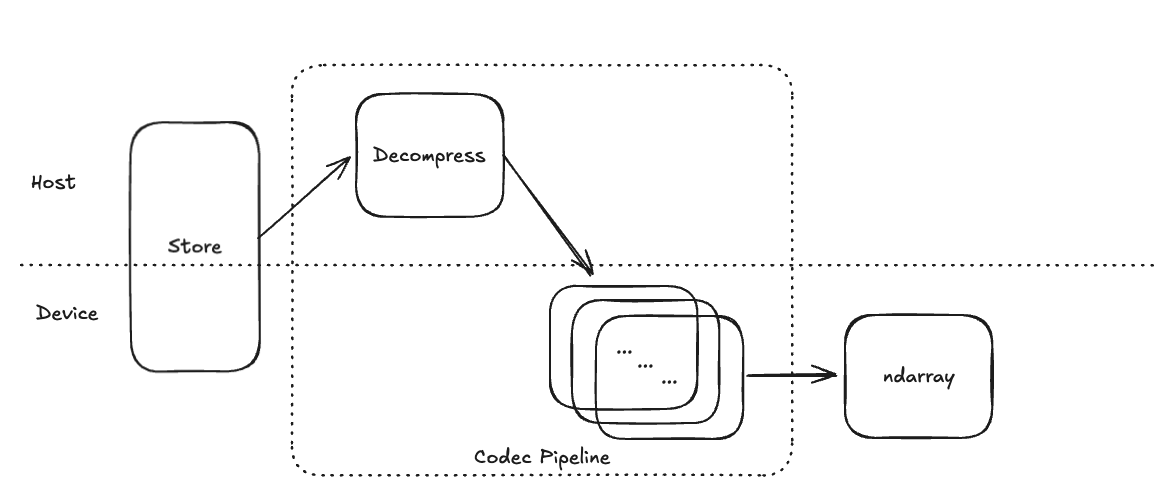
This will read the data directly from the Zarr store to GPU memory, significantly reducing I/O latency, especially for large datasets. However, it relies on the NVIDIA GPUDirect Storage (GDS) feature being enabled and correctly configured on your system.
Note: Even with GDS, the decompression step will still occur on the CPU (see next section for GPU solutions!). This means that the data is still being decompressed on the CPU before being transferred to the GPU. However, this is still a significant improvement over the previous method, as it reduces the amount of data that needs to be transferred over the PCIe bus. In the figure below, we show the flowchart of the data loading process with GDS enabled (i.e. using kvikio):
Step 3: GPU-based decompression with nvCOMP 🚀#
For a fully GPU-native pipline, the decompression step should also be done on the GPU. This is where NVIDIA's nvCOMP library comes in. nvCOMP provides fast, GPU-native implementations of popular compression algorithms like Zstandard (Zstd)
With nvCOMP, all steps of data loading including reading from disk, decompression, and transforming data can be done on the GPU, significantly reducing the time spent on data loading. Here is a flowchart of the data loading process with GDS and GPU-based decompression enabled:
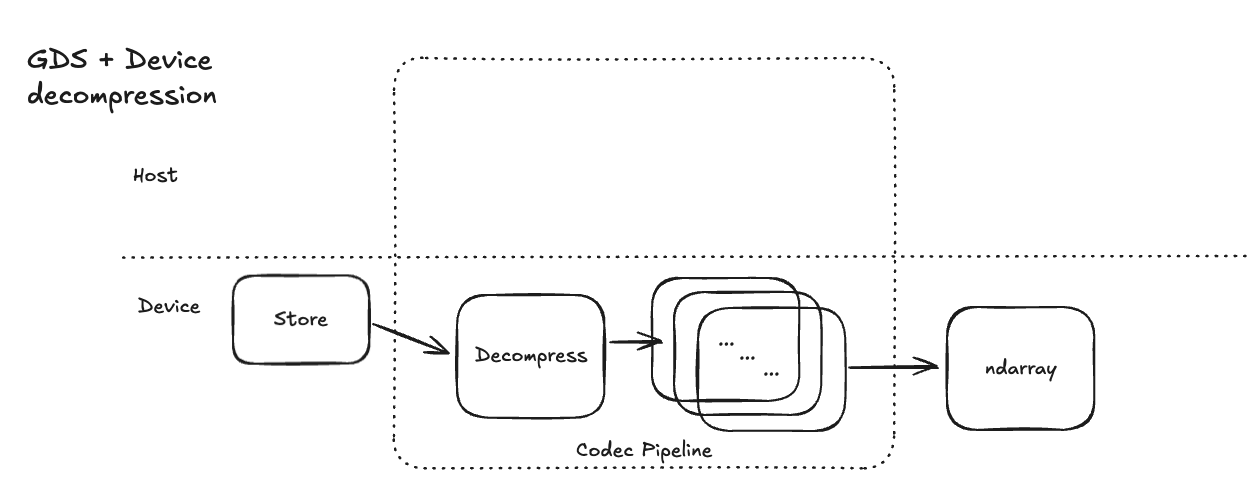
Sending compressed instead of uncompressed data to the GPU means less data transfer overall, reducing I/O latency from storage to device.
To unlock this, we would need zarr-python to support GPU-based decompression codecs, with one for Zstandard (Zstd) currently being implemented in this PR.
We tested the performance of GPU-based decompression using nvCOMP with Zarr v3 and KvikIO, and compared it to CPU-based decompression using this data reading benchmark here.
Here are the results:
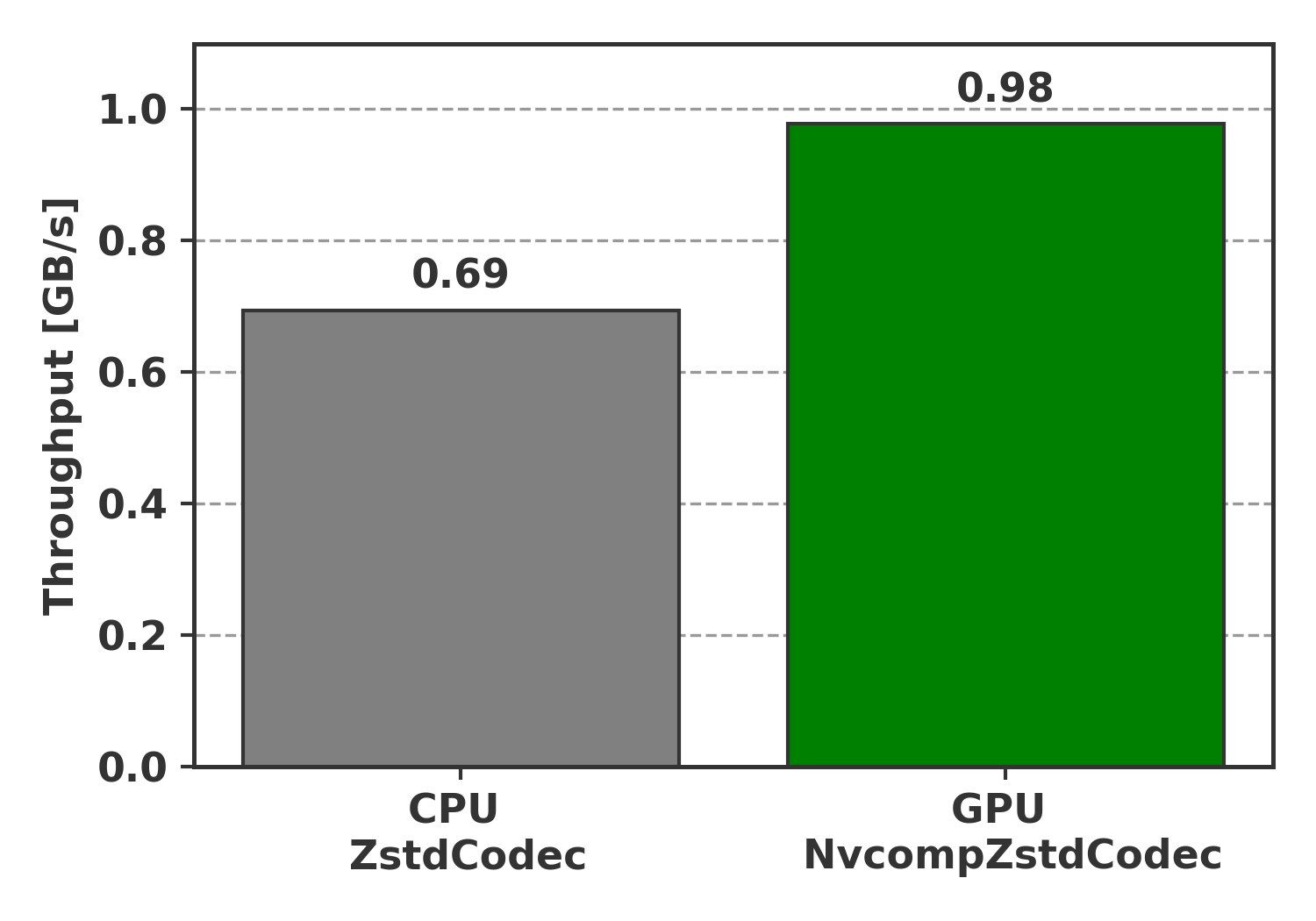
These results show that GPU-based decompression can significantly reduce the time spent on data loading and cut I/O latency from storage to device (less data transfer over PCIe/NVLink). This is especially useful for large datasets, as it allows for faster data loading and processing.
Keep an eye on this space, as we are working on integrating this into the Zarr ecosystem to enable GPU-based decompression for Zarr stores. This will allow for a fully GPU-native workflow, where all steps of data loading, including reading, decompression, and transforming data, can be done on the GPU.
💡 Takeaway: Even without full GDS support, GPU-based decompression can dramatically reduce I/O latency and free up CPU resources for other tasks.
Step 4: Overlapping CPU and GPU compute with NVIDIA DALI 🔀#
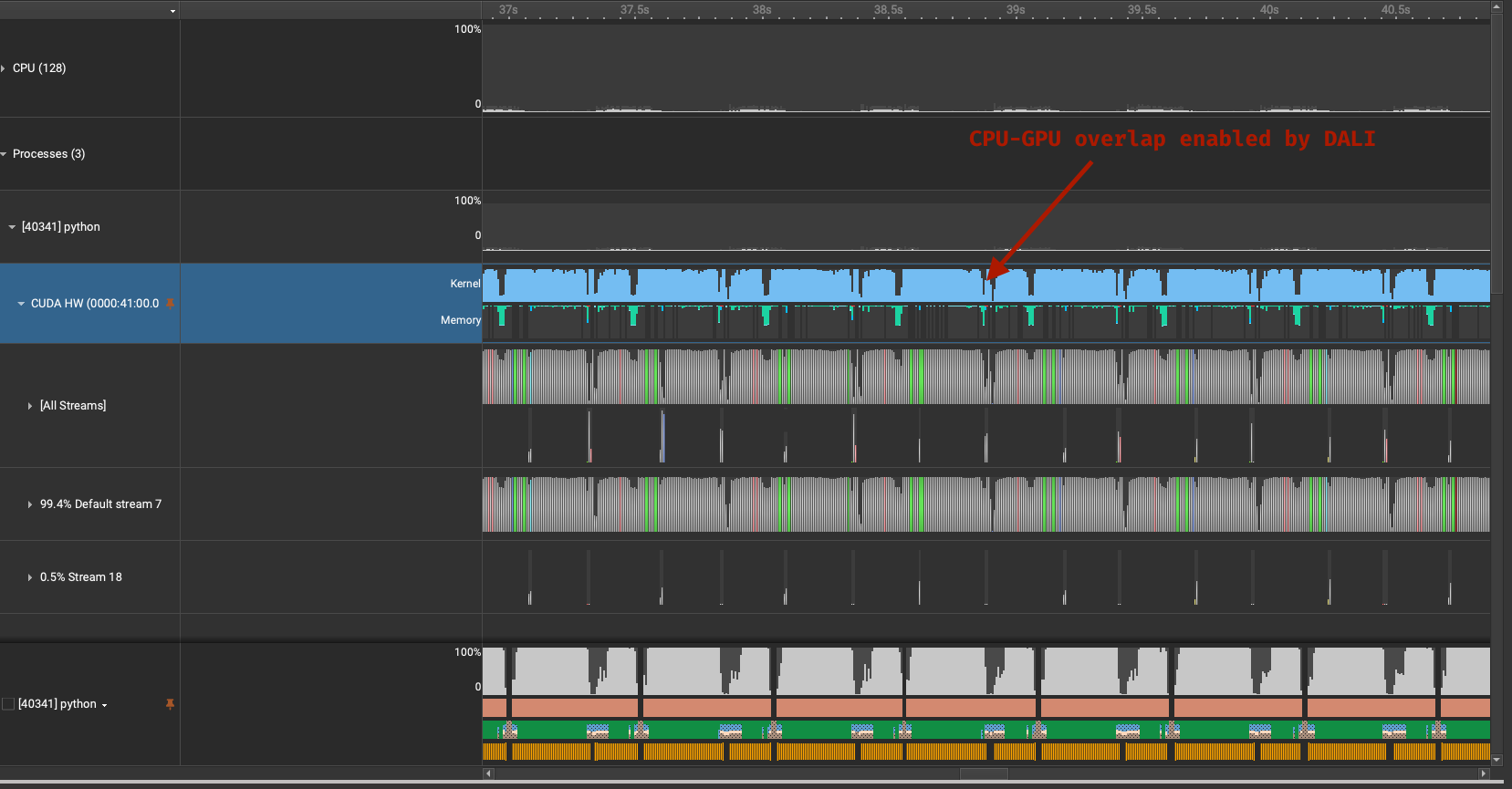
Ideally, we want to minimize idle time on both the CPU and GPU by overlapping their workloads. In traditional PyTorch DataLoaders, data loading and preprocessing often happen sequentially before GPU training can begin—this creates stalls where the GPU sits idle waiting for input (as seen in our baseline profiling screenshots above).
To address this inefficiency, we adopted NVIDIA DALI (Data Loading Library), which provides a flexible, GPU-accelerated data pipeline with built-in support for asynchronous execution across CPU and GPU stages. DALI helps reduce CPU pressure, enables concurrent preprocessing, and increases training throughput by pipelining operations.
First, we began with a minimal example in the zarr_DALI directory with short, contained examples of a DALI pipeline loading directly from Zarr stores. This example shows how to build a custom DALI pipeline that uses an ExternalSource operator to load batched image data from a Zarr store and transfer them directly to GPU memory using CuPy arrays.
In short, to use DALI with Zarr for data loading, you need to:
I. Define an external input iterator to read data from data source (e.g., Zarr store) and yield batches of data:
1class ExternalInputIterator: 2 def __init__(self, zarr_path="data/example.zarr", batch_size=16): 3 store = zarr.open(zarr_path, mode="r") 4 self.data_array = store[variable_name] 5 self.labels = store[label_variable_name] 6 self.batch_size = batch_size 7 self.indices = list(range(len(self.images))) 8 self.num_samples = len(self.data_array) 9 10 def __iter__(self): 11 self.i = 0 12 return self 13 14 def __next__(self): 15 batch, labels = [], [] 16 for _ in range(self.batch_size): 17 idx = self.indices[self.i % len(self.images)] 18 batch.append(self.data_array[idx]) 19 labels.append(self.labels[idx]) 20 self.i += 1 21 return batch, labels 22
II. Define a DALI pipeline: Use ExternalSource operator to read data from the iterator.
eii = ExternalInputIterator() pipe = dali.pipeline.Pipeline(batch_size=16, num_threads=4, device_id=0) with pipe: images, labels = fn.external_source( source=eii, num_outputs=2, device="gpu", # use GPU memory batch_size=16, )
III. Build and run the pipeline:
pipe.build() output = pipe.run() images_gpu, labels_gpu = output
Next, checkout the end-to-end example directory, where we showed how to use DALI to load data from Zarr stores, preprocess it on the GPU, and feed it into a PyTorch model for training.
Profiling results show that the DALI pipeline enables efficient overlap of CPU and GPU operations, significantly reducing GPU idle time and boosting overall training throughput.
Going Forward 🔮#
This work is still ongoing, and we are continuing to explore ways to optimize data loading and processing for large-scale geospatial AI/ML workflows. We started this work during a 3-day hackathon, and we are excited to continue this work in the future. During the hackathon, we were able to make significant progress in optimizing data loading and processing for large-scale geospatial AI/ML workflows.
We are continuing to explore the following areas:
- GPU Direct Storage (GDS) for optimal performance
- Better NVIDIA DALI integration for distributed training
- Support for sharded Zarr with GPU-friendly access patterns already merged in Zarr v3.0.8.
- Explore GDS for reading from cloud object storage instead of on-prem disk storage
- GPU-based decompression with nvCOMP
Lessons Learned 💡#
- Chunking matters! It really does and can make a huge difference in performance.
- Zarr Python 3 enables GPU-native workflows: Zarr Python 3 introduces experimental support for reading data directly into GPU memory via
zarr.config.enable_gpu(). However, this is currently limited to the final stage of the codec pipeline, with decompression still handled by the CPU. We are working on enabling GPU-native decompression usingnvCompto eliminate the host-device transfer. - Compression trade-offs: Using compression can reduce the amount of data transferred, but can also increase the time spent on decompression. We found that using Zarr v3 with GPU-based decompression can significantly improve performance.
- GPU-native decompression is a promising area for future work, but full support (e.g. GPU-side Zstd decompression) requires further development and testing.
- NVIDIA DALI is a powerful tool for optimizing data loading, but requires some effort to integrate into existing workflows.
- CuPy-Xarray integration is still a work in progress, but can be very useful for GPU-native workflows. Please see this PR for more details: xarray-contrib/cupy-xarray#70.
- NVIDIA Nsight provides a powerful tool for identifying bottlenecks.
Acknowledgements 🙌#
This work was developed during the NCAR/NOAA Open Hackathon in Golden, Colorado from 18-27 February 2025. We would like to thank the OpenACC Hackathon for the opportunity to participate and learn from this experience. Special thanks to NSF NCAR for providing access to Derecho supercomputer which we used for this project. A huge thank-you to our mentors from NVIDIA mentors, Akshay Subramaniam and Tom Augspurger, for their guidance and support throughout the hackathon.
Thanks also to the open-source communities behind Xarray, Zarr, CuPy, KvikIO, and DALI. And a special thanks to Deepak Cherian for providing guidance on Xarrary integration for reading from Zarr to GPU memory.
